
Overview

Speech data-mining procedure
We have collected our study participants' speech data from VR-based training sessions. Using the speech-recognition app, we converted students' audio data to textual data. Using the data-mining tool LightSIDE, We implemented a multi-label classification via supervised machine learning. The goal of the speech data-mining is to predict the competency improvement of adolescents with ASD. Below are the diagrams demonstrating how our speech data mining has been implemented in our project.
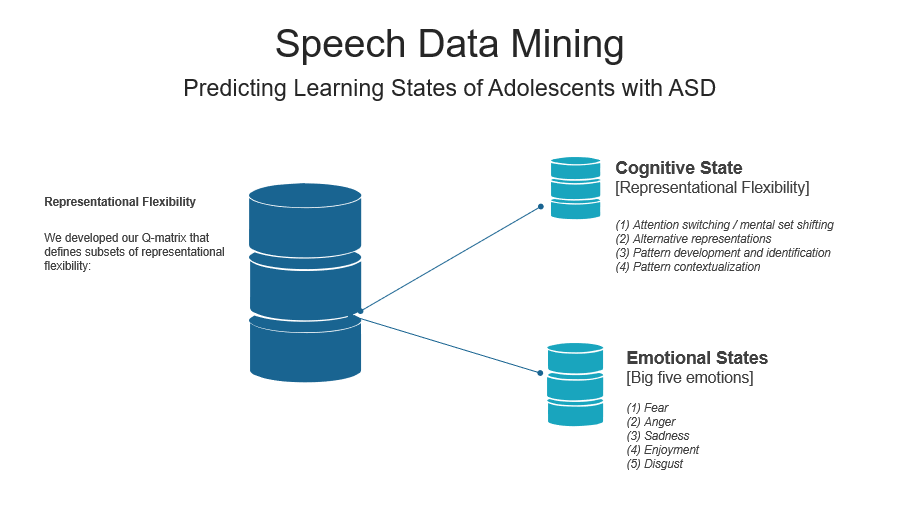
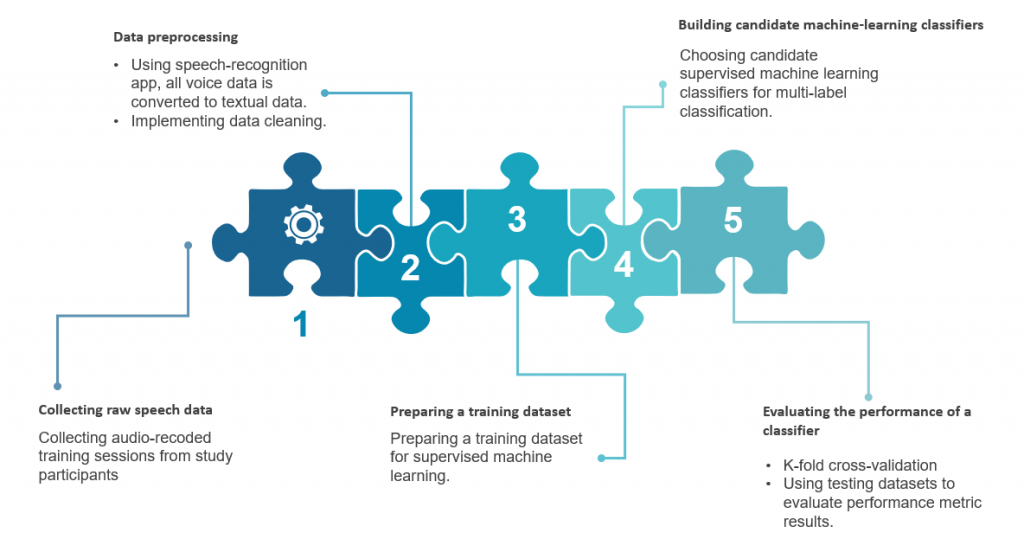
Log data-mining procedure
In addition to speech data mining, we also conducted log data-mining. Log data-mining in our project indicates the data-mining approach to collect students' design/scripting/movement behaviors that can represent their competency improvement. We defined a competency (representational flexibility) matrix that maps how each type of behavior logs is associated with the subsets of our target competency. Below is the flow chart displaying the entire procedure of our log data mining.
Specifically, in terms of the log data-mining procedure, first, we collected log data from adolescents with ASD. We made a list of observable variables on behaviors in a virtual world. Second, we then built an evidence-based design model that shows how each behavior log type will function as a data feature to predict a specific subset of our target competency. Third, we prepared a training dataset that contains random values ranging from the minimum and maximum values of the predefined scoring rule. We determined the range of our scoring rule based on the results of a pilot test, as well as expert reviews. Fourth, after we completed an initial model training, we tested candidate classifiers for supervised machine learning. Last, we iteratively evaluated the performance of the classifiers until we acquired the best prediction results.
